point-nerf

继承Nerf和深度多视图立体方法的优点
比Nerf快30倍
- 可以与其他3D重建方法结合

- 用0.2秒从三个输入视图生成点云

- 用20-40min训练得到的效果与Nerf训练20+hour 的效果相当甚至更好
主要特点
- 基于点云 P点:p位置,f神经特征向量( 局部3D场景信息 ),γ位于表面的可能性0-1
- 修剪和生长
- 可以对接各种获得稠密点云的方法,而不仅仅是MVSNet。
主要流程
- 输入照片 —> MVS生成深度图 —> 获得点云p、γ —> 渲染新视角(point-nerf) —> 更新点云

前置知识
MVS
MVSnet:从非结构化多视角立体中推断深度
网络输入:1张参考图像+N张原图像(从其他视角观察同一物体的图像),每张图像对应的相机内参和外参
网络输出:概率图+优化深度图,在后处理中使用概率图对优化深度图进行过滤

相关
参考
(96条消息) 从照片的三维重建(3D Reconstruction)——MVS系列(1)_yuboona的博客-CSDN博客_mvs算法
(96条消息) SFM 与MVS的区别_weeeeeida的博客-CSDN博客_sfm和mvs
(96条消息) 3D点云重建0-00:MVSNet(R-MVSNet)-目录-史上最新无死角讲解_江南才尽,年少无知!的博客-CSDN博客
总结
- 第一步获取稠密点云的方法不只MVS(6.4实验:用colmap点云转化到point-nerf,200k;提供极端示例,用非常稀疏的初始点云)
- 大规模3D场景的评估(ScanNet)
- 高效的临近神经点查询
- 高效的渲染方法

- 点云可能适合3D建模实体
问题
- [x] 啥是MVS
- [ ] 咋生成初始点云的
- [x] 为啥不能直接用,或者改进,或者用其他的(因为只有深度信息)
- [x] 篇尾总结
- [ ] point-nerf渲染:自己对自己没有影响吗?
- [ ] f到底是啥
- [ ] colmap咋就有点云了呢
PointNerf
体素渲染

c:像素点颜色,M:采样点个数,σ:体密度, τ:遮挡后剩余光, Δ:相邻样本距离,r:角度
输入输出
传统的NeRF模型直接利用MLP对光线上的采样点查询其辐射值r和体密度σ,而Point-NeRF对每个采样点,查询其在给定半径R(论文中没说取啥值)中的K个点,以采样点位置x,光线方向d以及K个点云作为输入,输出其辐射值和体密度。

1. 计算 
 :点云
:点云  对于采样点位置 x 的特征向量,
对于采样点位置 x 的特征向量, : 点云特征向量,x: 采样点位置, 代表点云 到采样点 x 的相对位置
: 点云特征向量,x: 采样点位置, 代表点云 到采样点 x 的相对位置

2. 计算 
:采样点的渲染后的特征向量,包括周围点的影响

3. 计算辐射值r

d是视角,R是多层感知器
4. 计算体密度σ

T是mlp

初始点云
获取图像深度

G是MVSnet,可以理解成 3D CNN模块
I是原图像,Φ是摄像机参数; additional neighboring views ( we use two additional views in most cases. )
获取特征f
将点云投影到reference image的特征图上,将投影点对应的特征向量(不同尺度下特征的聚合)作为点云的特征向量
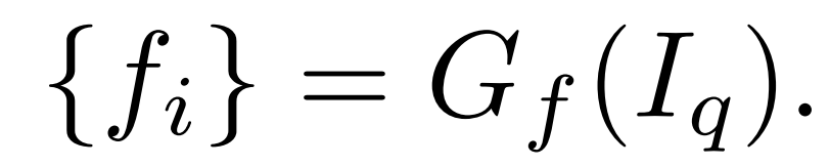
G是二维CNN( 带有3个下采样层的VGG网络 )
向量是56 ( 8 + 16 + 32 )通道, 最终的每个点的神经特征是59 通道的向量。
剪枝和生长
初始的点云往往有空洞或离群点,这会影响到渲染质量, 文章发现直接优化现存点的位置会让训练不稳定并且并不能填补大空洞 。
剪枝
γ:用sparsity loss优化,趋近于0或1

每10000次迭代就删去γ <0.1的点
生长
计算每条光线遮挡值最大的点

如果
 作为该点到它最近的神经点的距离
作为该点到它最近的神经点的距离
保证离表面近,离其他点远。
损失函数
Lrender:

Lsparse:

论文中采取 a = 2e-3
多想多做,发篇一作