文章概览
训练模型
先固定seed
1
2
3
4SEED = 1
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)先把模型化简:关闭数据增强或其他trick,他们可能带来愚蠢的bug
批数据过拟合:看看模型是否正确,验证模型能力
解决问题
loss下降中有一段上升
样本总量太小,突然出现一个差异很大的样本
数据集的label和特征不匹配
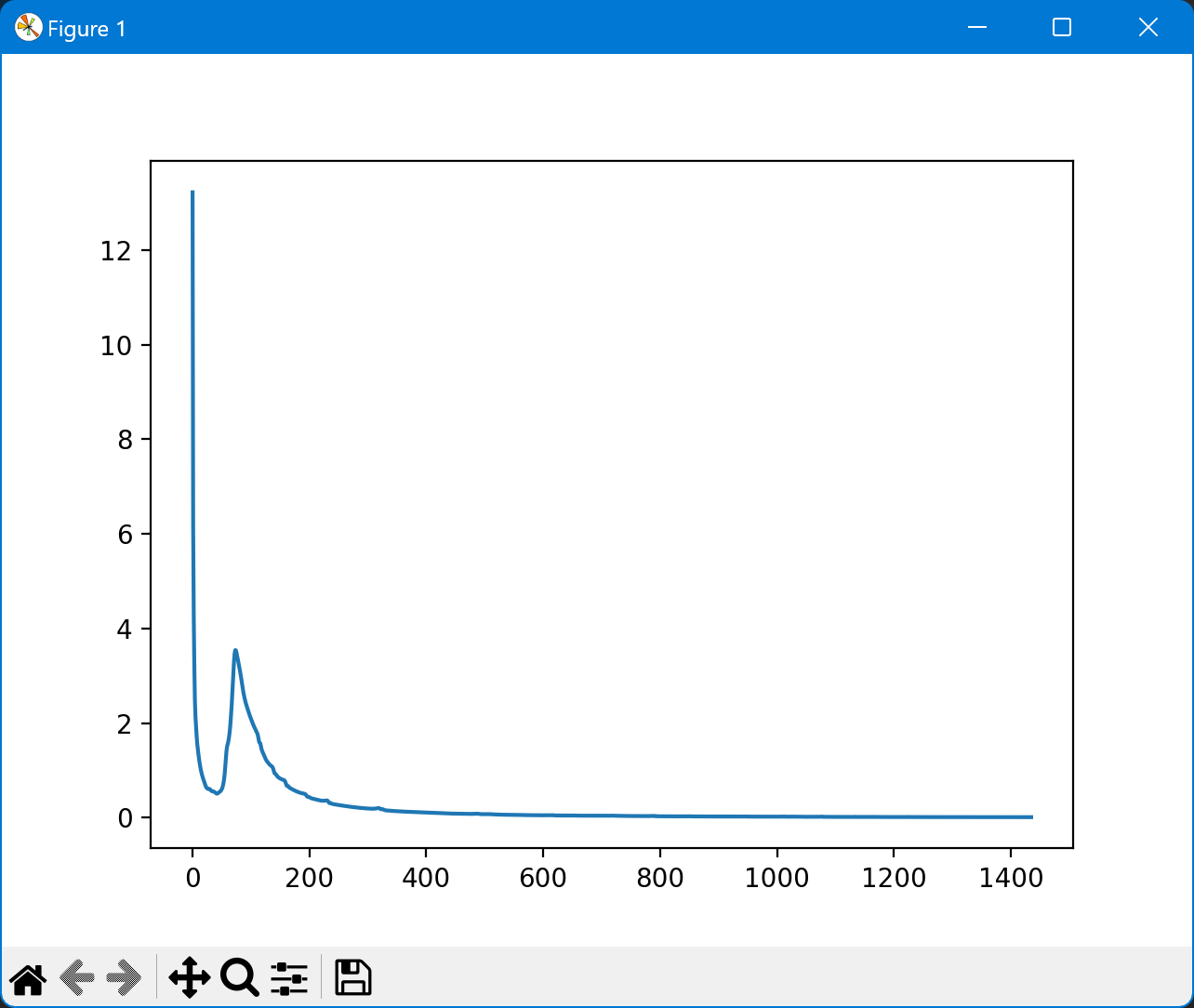
loss缓慢增大
如果迅速下降,并一直上升,可能是学习率过高
loss抖动得特别厉害
多半是lr太大,可以用lr decay
1 | my_optim = Adam(model.parameters, lr) |
loss周期性剧增
图片数量不能被batch size整除,最后一个batch图片数量少,随机性大
卷积层的大小设置不是很恰当
loss下降达一定程度后抖动
- batch_size较小
训练前配置
显存不足
可以调小bs,不过主要还是因为不够用,可以 nvidia-smi 看谁占了进程,给他 kill -9 [DIP] 咯。
持续看 watch -n 1 nvidia-smi
- 调小batchsize
- 释放内存
torch.cuda.empty_cache() - 查看所有的
.cuda()类型变量,尽量减少
图像评估
与图像大小有关
PSNR
Peak Signal-to-Noise Ratio 尖峰与噪声的比值
在保证两图像完整相似,又保证最大值很大(?没大理解,可能保证一些歪门邪道)
比较图像相似度最常用的判断指标。
越大越好,差不多37很大了。
ERGAS
Erreur Relative Globale Adimensionnelle de Synthèse
分辨率拉的越大,相对分值就高一些。μk是平均值。
类似PSNR,既保证图像相似,又保证均值大(可能防止一些歪门邪道)
是不是超分类特有的判断指标?
越小越好,可以到个位数
SAM
Spectral Angle Mapper计算光谱向量角度差
分别计算每个像素,最后求平均
越小越好,可以到个位数
MSE(mean square error)
直接均方根,逐个数据比较差距。
可以简称MSE或者RMSE(Root-Mean-Squared Error)。比较基础的。
越小越好。
多想多做,发篇一作